Semantic Outlier Removal with Embedding Models and LLMs
Abstract
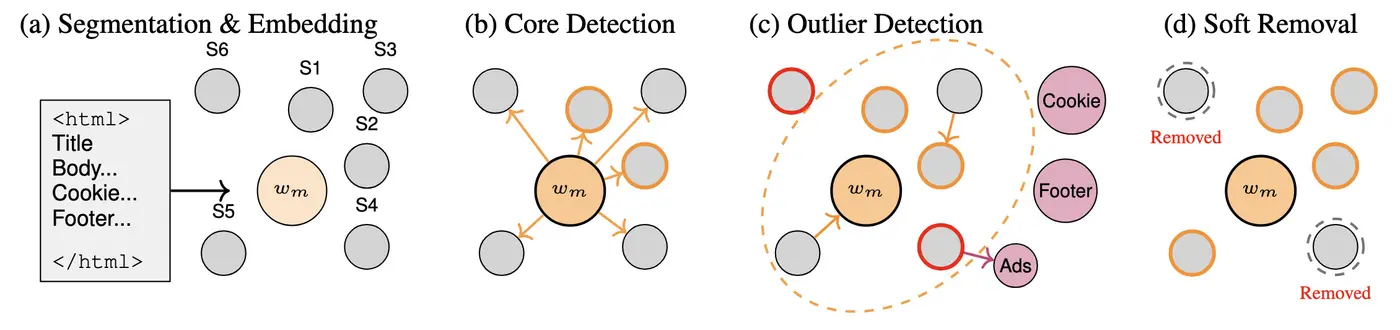
Modern text processing pipelines demand robust methods to remove extraneous content while preserving a document's core message. Traditional approaches—such as HTML boilerplate extraction or keyword filters—often fail in multilingual settings and struggle with context-sensitive nuances, whereas Large Language Models (LLMs) offer improved quality at high computational cost. We introduce SORE (Semantic Outlier Removal), a cost-effective, transparent method that leverages multilingual sentence embeddings and approximate nearest-neighbor search to identify and excise unwanted text segments. By first identifying core content via metadata embedding and then flagging segments that either closely match predefined outlier groups or deviate significantly from the core, SORE achieves near-LLM extraction precision at a fraction of the cost. Experiments on HTML datasets demonstrate that SORE outperforms structural methods and yield high precision in diverse scenarios. Our system is currently deployed in production, processing millions of documents daily across multiple languages while maintaining both efficiency and accuracy. To facilitate reproducibility and further research, we release our implementation and evaluation datasets.
BibTeX
@inproceedings{akbiyik2025semantic,
title={Semantic Outlier Removal with Embedding Models and {LLM}s},
author={Eren Akbiyik and Jo{\~a}o Almeida and Rik Melis and Ritu Sriram and Viviana Petrescu and Vilhj{\'a}lmur Vilhj{\'a}lmsson},
booktitle={ACL 2025 Industry Track},
year={2025}
}